今回は前回の固定長ファイルにおけるsubstringでの文字部分取り出しを使ったデータ整理の可変長(CSV)編です。
前回の記事はこちら。
大昔、とある数十万レコードで構成されるcsvをご提供いただいたことがございまして、そのファイル内容が安定しておらず
カンマの数が微妙に多いものがあったり、少なかったりと。
テキストデータで探すのはもちろん大変ですし、整形プログラムを作るのも面倒。
ということで、とりあえずデータベースのテーブルに突っ込んで、配列処理し、欠損レコードを除外すればいいや、ってことで以下の方法を取りました。
固定長の時と全く同じですね。
- 1つのtext型で構成される列のみを所持するテーブルを作成
- copyコマンドでローディング
- 可変長の構成通り、string_to_arrayで配列処理し、新たに列を用意して、create table as select …
では、早速。
データの準備
データは前回と同じ内容で、csvバージョンです。
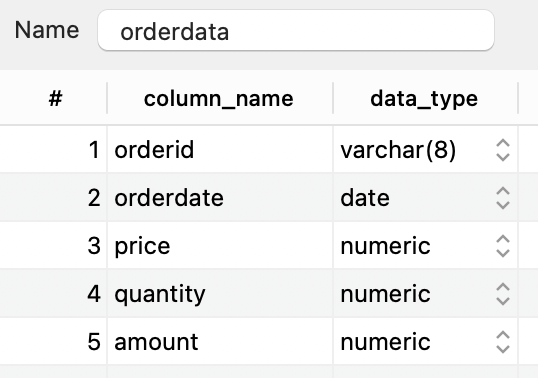
| 項目 | タイプ |
|---|---|
| orderid | 文字列 |
| orderdate | 日付 |
| price | 数値 |
| quantity | 数値 |
| amount | 数値 |
上記の構成について、以下のような「orderdata.txt」を用意しました。
2レコード目と3レコード目について
2レコード目はカンマの数が多い、3レコード目は最後の2項目が欠損している
A1000001,2020-03-25,550,5,2750
A1000001,2020-03-25,86,1,86,,,,,
A1000001,2020-03-25,150,
A1000001,2020-03-25,65,1,65
A1000001,2020-03-25,170,1,170
A1000001,2020-03-25,165,1,165
A1000001,2020-03-25,170,1,170
A1000002,2020-05-14,550,5,2750
A1000002,2020-05-14,86,1,86
A1000002,2020-05-14,150,1,150
A1000002,2020-05-14,65,1,65
A1000002,2020-05-14,170,1,170
A1000002,2020-05-14,165,2,330
A1000002,2020-05-14,170,1,170
A1000003,2020-02-11,550,4,2200
A1000003,2020-02-11,86,1,86
A1000003,2020-02-11,300,1,300
A1000003,2020-02-11,150,1,150
A1000003,2020-02-11,65,1,65
A1000003,2020-02-11,170,1,170テーブルの準備
「orderdata.csv」を格納するテーブルを作成します。
create table variablelength(
variablelength text
);
COPYコマンド
psqlの\copyで「orderdata.csv」を作成したテーブル「variablelength」にローディングします。
psql -h <ホスト名> -p 5432 -U <ユーザー名> -d <データベース名>
--csvを外す
\copy variablelength from '<フルパス>/orderdata.csv' with encoding 'utf-8' ;ちなみにこちらを以下のようなテーブル「orderdata」に
csv指定の以下のcopyコマンド
\copy orderdata from '<フルパス>/orderdata.csv' with encoding 'utf-8' csv;でロードすると以下のエラーが出ます。
2レコード目のエラー(カンマの数が多い)
ERROR: extra data after last expected column
CONTEXT: COPY orderdata, line 2: "A1000001,2020-03-25,86,1,86,,,,,"3レコード目のエラー(定義した列の数が足りない)
ERROR: missing data for column "amount"
CONTEXT: COPY orderdata, line 3: "A1000001,2020-03-25,150,"そこで、先に作成した「variablelength」テーブルの出番です。
variablelengthテーブルにcopyコマンドで「orderdata.csv」をセットします。
--csvを外す
\copy variablelength from '<フルパス>/orderdata.csv' with encoding 'utf-8' ;セットされたorderdata.csvの確認
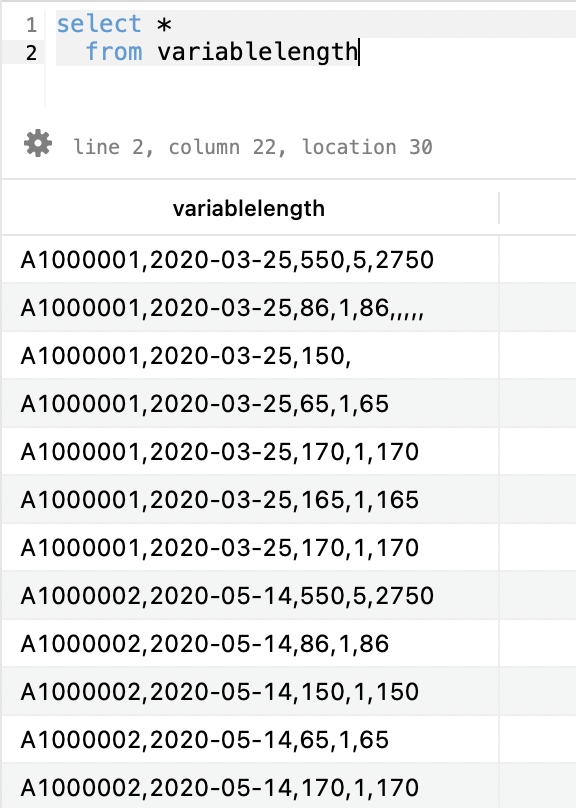
variablelength列にカンマ情報ありでセットされていることを確認できますね。
create table as select … で新規テーブルを作成
前回の固定長同様、以下の通り、データを区切って新たな列を作成、
新テーブル「orderdata」に値をセットします。
ここではstring_to_arrayを使います。
PostgreSQL 12.4文書
第9章 関数と演算子
9.18. 配列関数と演算子
https://www.postgresql.jp/document/12/html/functions-array.html
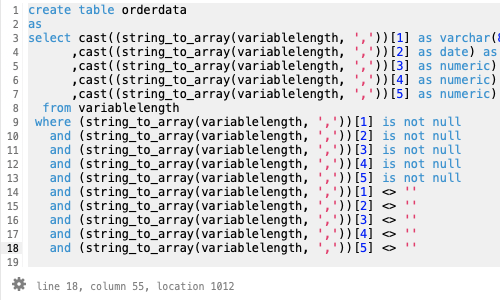
create table orderdata
as
select cast((string_to_array(variablelength, ','))[1] as varchar(8)) as orderid
,cast((string_to_array(variablelength, ','))[2] as date) as orderdate
,cast((string_to_array(variablelength, ','))[3] as numeric) as price
,cast((string_to_array(variablelength, ','))[4] as numeric) as quantity
,cast((string_to_array(variablelength, ','))[5] as numeric) as amount
from variablelength
--nullとブランクは欠損として扱い対象外とする
where (string_to_array(variablelength, ','))[1] is not null
and (string_to_array(variablelength, ','))[2] is not null
and (string_to_array(variablelength, ','))[3] is not null
and (string_to_array(variablelength, ','))[4] is not null
and (string_to_array(variablelength, ','))[5] is not null
and (string_to_array(variablelength, ','))[1] <> ''
and (string_to_array(variablelength, ','))[2] <> ''
and (string_to_array(variablelength, ','))[3] <> ''
and (string_to_array(variablelength, ','))[4] <> ''
and (string_to_array(variablelength, ','))[5] <> ''
結果は以下の通りです。
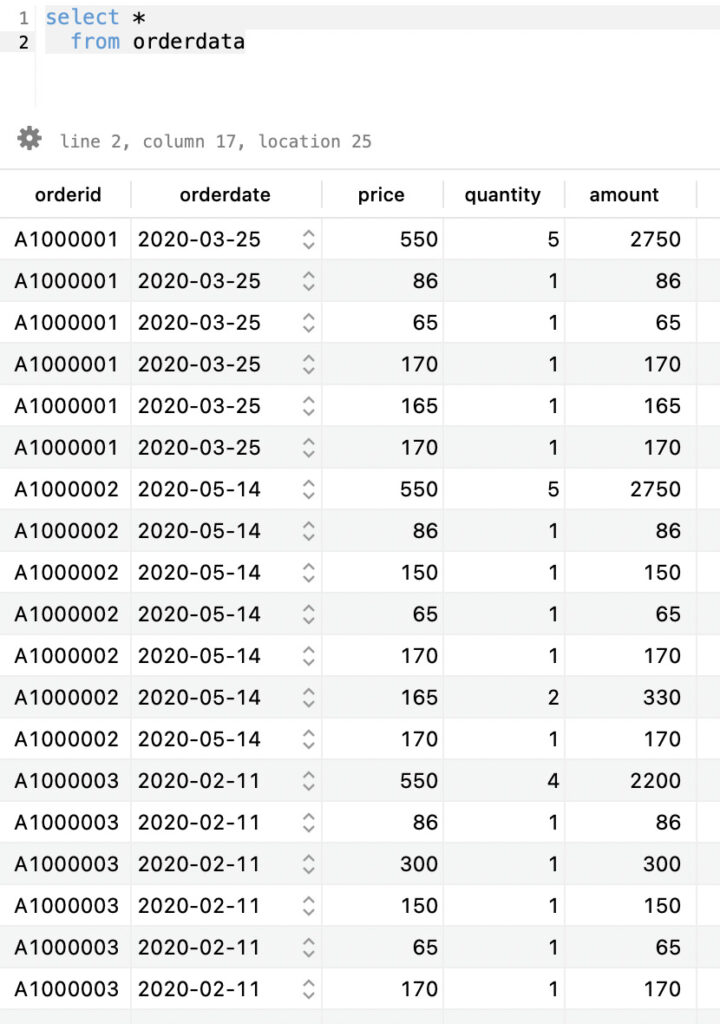
今回は3レコード目の
A1000001,2020-03-25,150,については4列目の数量(quantity)が存在しないので欠損レコードして、orderdataテーブルにセットしませんでした。
いかがでしたでしょうか?
あまりこのような状況になることはないのですが、
string_to_arrayの使い方のご紹介記事でした。
以上です。
では。