
Twitterを始めとしたSNSの普及に伴い、インターネット上は多くのテキストで溢れていますね。
企業活動をする上で、自社のプロダクトやサービスに対する
ユーザーの声を拾うにはとても簡単な世の中になったと感じている方も多くいることでしょう。
しかしながら、膨大なテキストデータの中から、一件一件、全て目を通していくには多くの時間を要します。
そこで感情分析を用いて、肯定的な意見(Positive)なのか、否定的な意見(Negative)なのか、それとも中立的な意見(neutral)なのかを数値化(PN値)し、
その数値で持って、分類してから、声を拾うというプロセスを組みれば分析業務も捗ります。
今回は感情分析をする上で重要な前処理となります、形態素解析のできるMeCabをご紹介したく思います。
感情分析についてはWikipediaをご参考ください。
Sentiment analysis
Sentiment analysis (also known as opinion mining or emotion AI) refers to the use of natural language processing, text analysis, computational linguistics, and biometrics to systematically identify, extract, quantify, and study affective states and subjective information. Sentiment analysis is widely applied to voice of the customer materials such as reviews and survey responses, online and social media, and healthcare materials for applications that range from marketing to customer service to clinical medicine.
出典:https://en.wikipedia.org/wiki/Sentiment_analysis
形態素解析
形態素解析・・・
あまり聞かない言葉で、初めて聞いた方も多いかと思います。
恥ずかしながら、自分自身もここ数年で知った言葉です。
形態素解析の解説については、毎度で恐縮ですが、Wikipediaをご参考ください。
形態素解析
形態素解析(けいたいそかいせき、Morphological Analysis)とは、文法的な情報の注記の無い自然言語のテキストデータ(文)から、対象言語の文法や、辞書と呼ばれる単語の品詞等の情報にもとづき、形態素(Morpheme, おおまかにいえば、言語で意味を持つ最小単位)の列に分割し、それぞれの形態素の品詞等を判別する作業である。自然言語処理の分野における主要なテーマのひとつであり、機械翻訳やかな漢字変換など応用も多い(もちろん、かな漢字変換の場合は入力が通常の文と異なり全てひらがなであり、その先に続く文章もその時点では存在しないなどの理由で、内容は機械翻訳の場合とは異なったものになる)。
出典:https://ja.wikipedia.org/wiki/%E5%BD%A2%E6%85%8B%E7%B4%A0%E8%A7%A3%E6%9E%90
今回はこの一連の処理ができるライブラリであるMeCabを使って、とあるアンケート結果を単語に分けるまでの処理をいたします。
実際の感情分析については、また日を改めて実施いたします。
MeCabをインストールする
まずはMeCabをインストールします。
詳細はこちらをご参考ください。
mecab-python3 1.0.3
Python wrapper for the MeCab morphological analyzer for Japanese
出典:https://pypi.org/project/mecab-python3/
pipコマンドで以下を実行します。
pip install mecab-python3
今回の目標
今回は以下のような処理結果になるようにいたします。
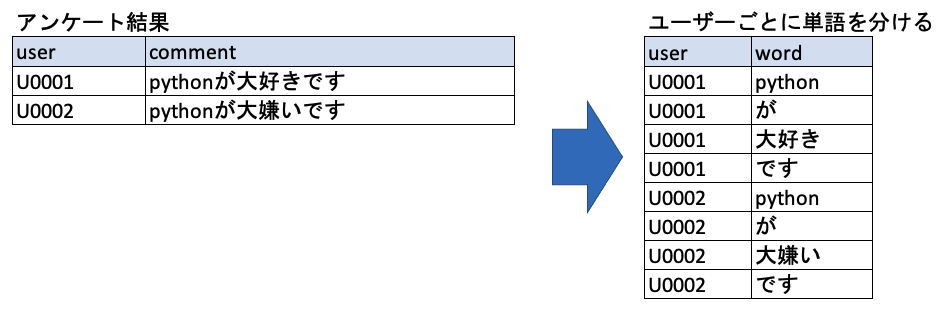
アンケート結果に対して、各アンケートを答えた人単位に単語を分け、データセットするまでとします。
データの準備
以下のようなCSVデータ(data.csv)を用意しました。
とあるボクシングの試合に対する視聴者の感想です。
| user | comment |
|---|---|
| U0001 | 伊藤のハンドスピードには目を見張るものがあった。 |
| U0002 | 伊藤のスピードに徐々にとはいえ、最終的にそのスピードに順応した加藤の調整力が素晴らしかった。 |
| U0003 | 本試合は終始、加藤の攻守に渡って高レベルのボクシング技術を見せつける内容だった。 |
| U0004 | 伊藤は軽量級の選手かと思うほどの軽快な動きで驚きっぱなしであり、日本人離れしている。 |
| U0005 | 加藤の空間把握能力とリング全体を見下ろす俯瞰力で持って、試合をコントロールしていた。 |
| U0006 | まだ2月であるが、この試合は確実に今年のベストマッチ賞に選ばれる。 |
| U0007 | 結局、判定までもつれてしまうが、見応えのある試合でとても満足している。 |
| U0008 | 一見、加藤が試合をコントロールしていたと見えるが、積極性という観点からは伊藤の方が優れていた。判定には納得できない。 |
| U0009 | もっと大きな舞台でこの試合を見たかった。リマッチを希望。 |
| U0010 | 加藤のディフェンスからのオフェンスへのシームレスな転換が最終的なジャッジになったと思われる。例え、積極性があり、手数が多いとはいえ、有効打がなければ意味がない。 |
Pythonコード
今回は単純にCSVを読み込んで、最終アウトプットとしてCSVに吐き出すだけでなく
視覚的に処理結果を見るためにJupyter notebookでPandasを使いコードを書きました。
①CSVデータをPandasデータフレームにデータセットする
まず、CSVデータ(data.csv)を以下の通り、データフレームdfにセットします。
#Pandasをimport
import pandas as pd
#csvファイルをData Frameに読み込む
df = pd.read_csv("data.csv")
#表示
df結果は以下の通りです。

②MeCabを使って、各アンケート結果を回答者毎に単語を分ける
続いてMeCabを使って、各回答者のアンケート結果の文章を単語に切り分けます。
分かりやすくするため、MeCabで取得できた情報(単語のみでなく品詞等も含め)、データフレームにセットします。
#MeCab等、必要なパッケージをimport
import MeCab
import re
#MeCabのインスタンスを作成する
mecab = MeCab.Tagger('')
#最終的な結果を出力するためのData Frameを作成する
df1 = pd.DataFrame( columns=['user','word0','word1','word2','word3','word4','word5','word6'] )
#dfにセットしたcsvファイルを一行ずつ読み込む
for row, item in df.iterrows():
#形態素解析結果をセットする変数。一行ずつ(opinionaireid単位)処理するため、処理前に一度クリアする
result = ''
#一行ずつ形態素解析を行い、単語ごとに分ける
result = mecab.parse(item.comment)
#一行ごとに分けて変数にセットする
lines = result.split("\n")
#後ろから2列は不要のため削除する
lines = lines[0:-2]
#一行ずつに分けた形態素解析結果の変数を上から順に読み込む
for words in lines:
#タブとカンマで区切られているため、配列して新たな変数にセットする
word = re.split('\t|,',words)
#結果をData Frameにセットする
df1 = df1.append({'user':item.user, 'word0':word[0], 'word1':word[1], 'word2':word[2], 'word3':word[3], 'word4':word[4], 'word5':word[5], 'word6':word[6]},ignore_index=True)
#全件表示
pd.set_option('display.max_rows', None)
#Data Frameの中身を表示する
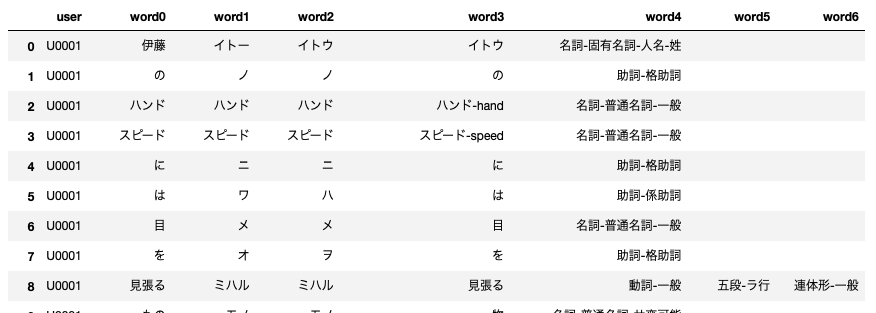
df1結果は以下の通り。
いかがでしたでしょうか?
今回はMeCabの形態素解析のイメージをご理解いただくために
感情分析をするための準備の準備レベルの処理に留まりましたが、
単純に今回の結果の単語の使用回数を積み上げるだけで、ある程度、そのアンケート結果の印象だけでも感じとることができるのでは?と思います。
次回以降、感情分析や単語単語の関連性を図示する方法等をご紹介いたします。
では。
形態素解析の説明が素晴らしいと思います。感情分析については、とても興味がありますね。次回pythonで感情分析の部分を更新して頂きお待っています。